GPT4All 官网给自己的定义是:一款免费使用、本地运行、隐私感知的聊天机器人,无需GPU或互联网。
OpenAI发布的ChatGPT热度一直不减。虽然它强大,但由于它几乎不可能开源,且参数数量过于庞大(GPT-3已经达到1750亿),不管对它进行训练、微调或者运行,都需要强大的硬件设备支持,个人和团队很难负担得起相关费用。不少研究人员使用了前不久Meta开源的LLaMA模型(参数数量从70亿到650亿不等),并在之上进行微调。
例如斯坦福在LLaMA基础之上的微调模型Alpaca,只有70亿参数。性能可媲美 GPT-3.5 这样的超大规模语言模型GPT4All,也是一种基于 LLaMA 的新型 7B 语言模型。
它支持多种模型,并且集成了模型下载
GPT4ALL不单是一个chatbot软件,而是一个生态系统。用于训练和部署强大且可定制的大型语言模型,可以在消费级CPU上本地运行。它的目标是成为最好的指令微调型的语言助手模型,任何个人或企业都可以自由使用、分发和构建。
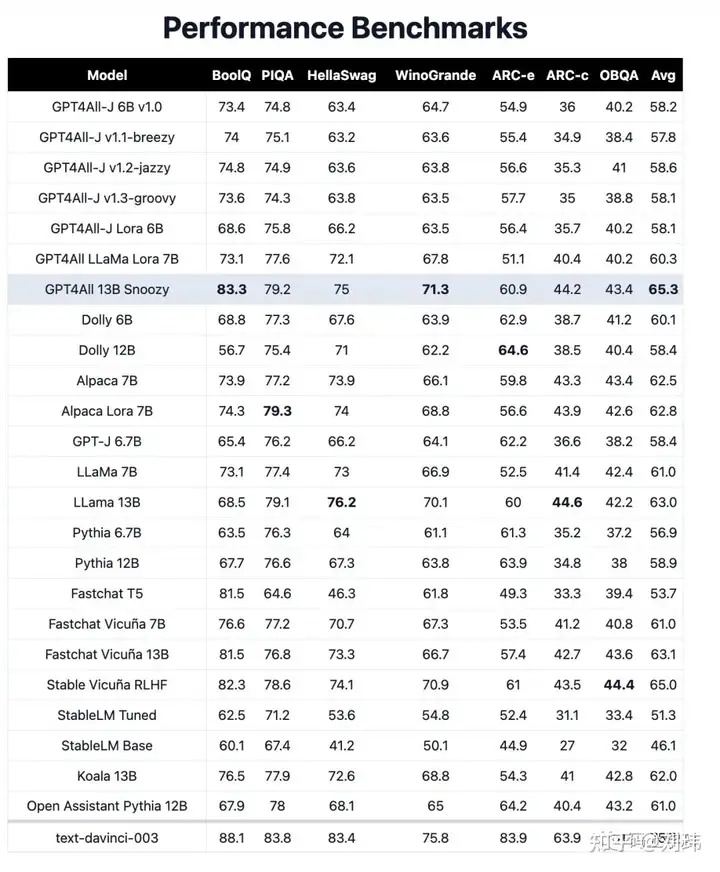
我觉得GPT4ALL最大的优点就是开源且能商用,不管是个人还是企业,在不想数据泄露给他人的情况下,能够私有部署和快速训练自己的GPT。而且GPT4All 13B(130亿参数)模型性能直追1750亿参数的GPT-3。
根据研究人员,他们训练模型只花了四天的时间,GPU 成本 800 美元,OpenAI API 调用 500 美元。这成本对于想私有部署和训练的企业具有足够的吸引力。低成本对于研究人员也更友好,他们能快速迭代模型,以进行更多的探索。
下图是GPT4ALL官方提供的各种模型性能评分,最下面的text-davinci-003就是openai的GPT-3.5模型:
模型介绍
GPT4All支持多种不同大小和类型的模型,用户可以按需选择。
序号 模型 许可 介绍
1 ggml-gpt4all-j-v1.3-groovy.bin 商业许可 基于GPT-J,在全新GPT4All数据集上训练
2 ggml-gpt4all-113b-snoozy.bin 非商业许可 基于Llama 13b,在全新GPT4All数据集上训练
3 ggml-gpt4all-j-v1.2-jazzy.bin 商业许可 基于GPT-J,在v2 GPT4All数据集上训练。
4 ggml-gpt4all-j-v1.1-breezy.bin 商业许可 基于GPT-J,在v1 GPT4All数据集上训练
5 ggml-gpt4all-j.bin 商业许可 基于GPT-J,在v0 GPT4All数据集上训练
6 ggml-vicuna-7b-1.1-q4_2.bin 非商业许可 基于Llama 7b,由加州大学伯克利分校、加州大学医学院、斯坦福大学、麻省理工大学和加州大学圣地亚哥分校的团队训练。
7 ggml-vicuna-13b-1.1-g4_2.bin 非商业许可 基于Llama 13b,由加州大学伯克利分校、加州大学医学院、斯坦福大学、麻省理工大学和加州大学圣地亚哥分校的团队训练。
8 ggml-wizardLM-7B.q4_2.bin 非商业许可 基于Llama 7b,由微软和北京大学训练。
9 ggml-stable-vicuna-13B.q4_2.bin 非商业许可 基于Llama 13b和RLHF,由Stable AI训练
GPT4All的模型是一个 3GB - 8GB 的文件,目前由Nomic AI进行维护。
nomic.ai 公司
模型的维护公司nomic.ai是怎样一家公司,它为什么要免费开发和维护这些模型呢?它在官网上是这样写的:
现在,由于人工智能的兴起,我们的世界正在发生巨大的变化。现代人工智能模型在互联网规模的数据集上进行训练,并以前所未有的规模制作内容。它们正在迅速渗透到地球上的每一个行业——从国防、医药、金融到艺术。
对这些模型的访问由少数资金充足、越来越隐秘的人工智能实验室控制。如果这种趋势持续下去,人工智能的好处可能会集中在极少数人手中。
我们的 GPT4All 产品实现了前所未有的AI访问,让任何人都能从AI技术中受益,而不受硬件、隐私或地缘政治限制。
一句话来说:担心AI技术被少数人控制,并且对此付诸实际行动。
LLM大语言模型
gpt4all使用的模型是大语言模型(Large Language Model),它采用深度学习方法来理解和生成自然语言文本。这些模型通过在大量文本数据上进行训练,学习到丰富的语言知识和基于上下文的语义理解。一旦训练完成,大语言模型可以用来完成问题回答、文本生成、语言翻译等多种任务。
最常用的大语言模型架构是Transformer,它由Google Brain的一个团队在2017年提出。这种架构采用自注意力机制(Self-Attention Mechanism),能够捕捉文本中长距离的依赖关系。随着模型大小和训练数据量的增加,大语言模型的性能也在不断提高。
例如,OpenAI发布了如GPT(Generative Pre-trained Transformer)等一系列大语言模型。GPT-3是其中的一个代表性模型,拥有1750亿个参数,表现出了强大的生成能力和多任务学习能力。
GPT-J语言模型
gpt4all使用的语言模型主要分两类:GPT-J和LLaMA。
GPT-J 是一个在 Pile 上训练的 60 亿参数开源英语自回归语言模型。由 EleutherAI 在2021年发布,它遵循了GPT-2的架构,在发布时,它是世界上最大的公开可用的 GPT-3 风格语言模型。GPT-J的任务表现和OpenAI的GPT-3版本非常相似,甚至在代码生成水平上还要略胜一筹。
最新版本GPT-J-6B是基于一个开源的825GB精选语言建模数据集The Pile生成。
LLaMA语言模型
LLaMA(Large Language Model Meta AI)是一种大语言模型,它是由Meta AI研究团队2023年开发的,用于自然语言处理任务。LLaMA 使用 transformer 架构。
LLaMA 的开发人员曾报告说,LLaMA使用130亿参数的模型在大多数NLP基准测试中的性能超过了更大的GPT-3(具有1750亿参数)
我想等网站访问量多了,在这个位置放个广告。网站纯公益,但是用爱发电服务器也要钱啊 ----------狂奔的小蜗牛
