Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。它的宗旨是让最先进的 NLP 技术人人易用。
Transformers 提供了便于快速下载和使用的API,让你可以把预训练模型用在给定文本、在你的数据集上微调然后通过 model hub 与社区共享。同时,每个定义的 Python 模块均完全独立,方便修改和快速研究实验。
Transformers 支持三个最热门的深度学习库: Jax, PyTorch 以及 TensorFlow — 并与之无缝整合。你可以直接使用一个框架训练你的模型然后用另一个加载和推理。
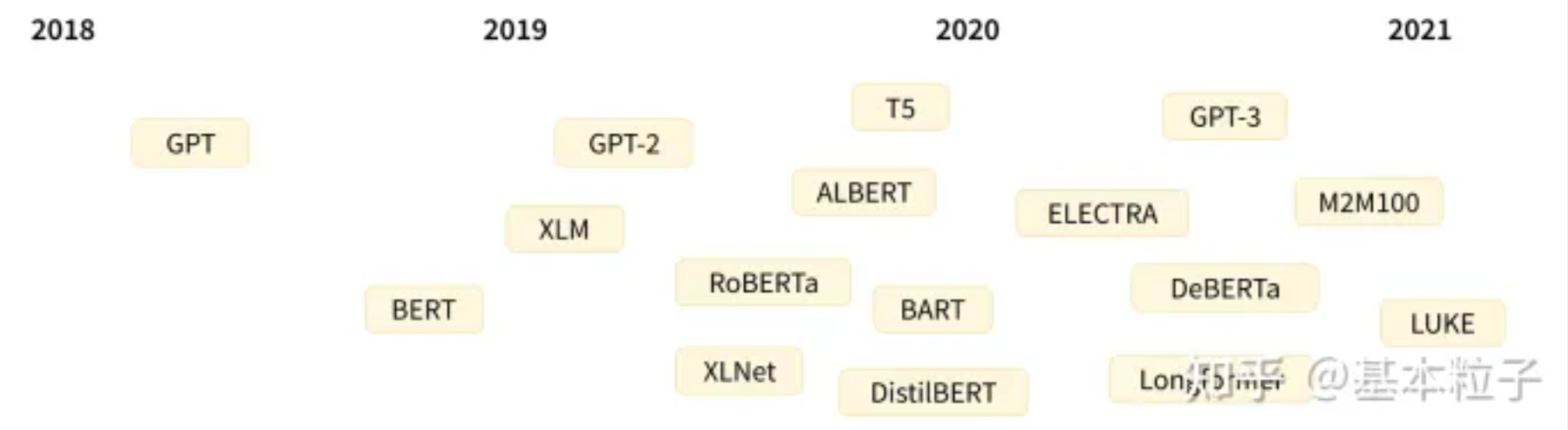
下图是一张来自于官网的Transformers发展谱系图,短短3,4年就发展出了庞大家族。
便于使用的先进模型:
更低计算开销,更少的碳排放:
对于模型生命周期的每一个部分都面面俱到:
为你的需求轻松定制专属模型和用例:
Trainer API 并非兼容任何模型,只为本库之模型优化。若是在寻找适用于通用机器学习的训练循环实现,请另觅他库。
Transformers开发背后的故事:
Hugging face 起初是一家总部位于纽约的聊天机器人初创服务商,他们本来打算创业做聊天机器人,然后在github上开源了一个Transformers库,虽然聊天机器人业务没搞起来,但是他们的这个库在机器学习社区迅速大火起来。目前已经共享了超100,000个预训练模型,10,000个数据集,变成了机器学习界的github。
其之所以能够获得如此巨大的成功,一方面是让我们这些甲方企业的小白,尤其是入门者也能快速用得上科研大牛们训练出的超牛模型。另一方面是,这种特别开放的文化和态度,以及利他利己的精神特别吸引人。huggingface上面很多业界大牛也在使用和提交新模型,这样我们就是站在大牛们的肩膀上工作,而不是从头开始,当然我们也没有大牛那么多的计算资源和数据集。
在国内huggingface也是应用非常广泛,一些开源框架本质上就是调用transfomer上的模型进行微调(当然也有很多大牛在默默提供模型和数据集)。很多nlp工程师招聘的条目上也明摆着要求熟悉huggingface transformer库的使用。简单介绍了他们多么牛逼之后,我们看看huggingface怎么玩吧。因为他既提供了数据集,又提供了模型让你随便调用下载,因此入门非常简单。你甚至不需要知道什么是GPT,BERT就可以用他的模型了(当然看看我写的BERT简介还是十分有必要的)。下面初步介绍下huggingface里面都有什么,以及怎么调用BERT模型做个简单的任务。
我想等网站访问量多了,在这个位置放个广告。网站纯公益,但是用爱发电服务器也要钱啊 ----------狂奔的小蜗牛
